Hello everyone, in this tutorial I want to provide you with a simple as possible, yet comprehensive enough example of what loose coupling really is and why it’s useful. Understand loose coupling and you’re going to have another advanced software engineering concept under your belt.
Before we start, I’m going to borrow the Loose Coupling definition from Wikipedia:
In computing and systems design a loosely coupled system is one in which each of its components has, or makes use of, little or no knowledge of the definitions of other separate components. Sub-areas include the coupling of classes, interfaces, data, and services.
The key takeaway from this is the phrase “little to no knowledge”. Object oriented programming and design offers multiple layers of abstraction for your application. That’s another key-word, “Abstraction”. Everyone who has ever taken a course on OOP or read an OOP book has stumbled upon this word and probably knows how OOP helps you achieve Polymorphism. The benefits of loose coupling include:
• Cleaner Code: After applying loose coupling your code is going to be much easier to read
• More Maintainable Code: Your code will also be easier to change
• Testable Code: This is the reason why beginners see no need for loose coupling. Because most beginners do not unit test and don’t know how hard it is to unit test tightly coupled code
• Scalable Code: I understand that in a small application loose coupling might not make any noticeable difference but in large scale projects it just makes your life a lot easier
The easiest way to explain loose coupling is actually to explain the exact opposite, tight coupling. Tight coupling is when one or more classes in your application is highly dependent on one or more other classes. Take this class hierarchy for example:
class ClassA
{
public ClassA() { }
}
class ClassB
{
public ClassB()
{
_foo = new ClassA();
}
private ClassA _foo;
}
In this simple example, ClassB contains an instance of ClassA and ClassB is responsible for creating that instance. So in this implementation ClassB needs to have knowledge about the inner workings of ClassA. Remember that we want ClassB to have little or no knowledge about how ClassA operates or how its objects get instantiated. The above code using loose coupling will look like this:
class ClassA : IMyInterface
{
public ClassA() { }
}
class ClassB
{
public ClassB(IMyInterface foo)
{
_foo = foo;
}
private IMyInterface _foo;
}
An interface, in this very simplistic example called MyInterface, is introduced to solve the conflict. That way, any class that implements IMyInterface can be passed to class B who no longer needs to know how to instantiate it.
To provide a more real-world example, I will create a Console Application project with some rather simple functionality. It’s going to display some to-dos in the console and whether those To-Dos have been completed or not. (The full code of this project can be found here).
I’m going to create a “Models” folder to place my ToDo class first:
I tried to keep it as simple as possible, after all this is just a console application.
Next let’s create the class with the basic to-do functionality. For the sake of demonstration I’m going to actually create two classes. One will be tight coupled, the other will be loosely coupled. Let’s name them TightlyCoupledToDos and LooselyCoupledToDos respectively.
For now the two classes are essentially identical:
public class TightlyCoupledToDos
{
public class TightlyCoupledToDos
{
}
public async Task<IEnumerable<ToDo>> All()
{
}
}
public class LooselyCoupledToDos
{
public LooselyCoupledToDos()
{
{
public IEnumerable<ToDo> All()
{
}
}
Both have an All() method that returns a list of to-dos. The interesting part in how these two classes are going to populate the to-do list. In a real world application data like that probably come from a service. So let’s go ahead and create our ToDoService in a ‘Services’ folder:
public class ToDoService
{
public IEnumerable<ToDo> GetAll()
{
}
}
This is an initial form of the service. Because we don’t have an API or a database we are going to fetch data from JSONPlaceholder’s ToDo list which can be found here https://jsonplaceholder.typicode.com/todos
To parse the JSON data we will use Newtonsoft’s NuGet package. To add it:
• Right click on your project
• Go to ‘Manage NuGet Packages’
• Go to the ‘Browse’ tab
• Search for ‘Newtonsoft.Json’
• Click Install
Next we will use an HttpClient and the Newtonsoft.JsonConvert class to get the data from the API and parse them to a list of ToDo objects:
A simple enough, service implementation. It uses an instance of the HttpClient class to asynchronously read JSON data the feed them to the Json Converter for deserialization.
After having created the service, let’s use it in our TightlyCoupledToDos class to get some data.
You see the service in initialized in the constructor and the All() method uses the service to get the parsed data and return it
Let’s go in our Program.cs file to make use of the TightlyCoupledToDos class and display the list of to-dos on screen
class Program
{
static void Main(string[] args)
{
ToDos();
Console.ReadLine();
}
static async void ToDos()
{
TightlyCoupledToDOs vm = new TightlyCoupledToDos();
IEnumerable<ToDo> todos = await vm.all();
foreach(ToDo todo in todos)
{
Console.WriteLine(todo);
}
}
}
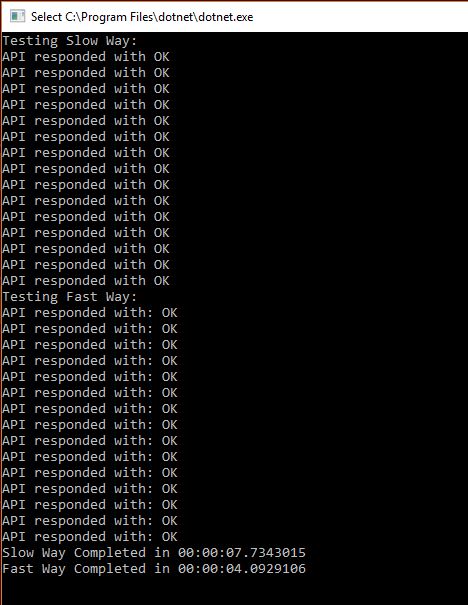
The Console.ReadLine() statement is there to keep the console window open for us, so that we can see the results. The ToDos() method instantiates the TightlyCoupledToDos class, gets the todos asynchronously and writes them to the output:
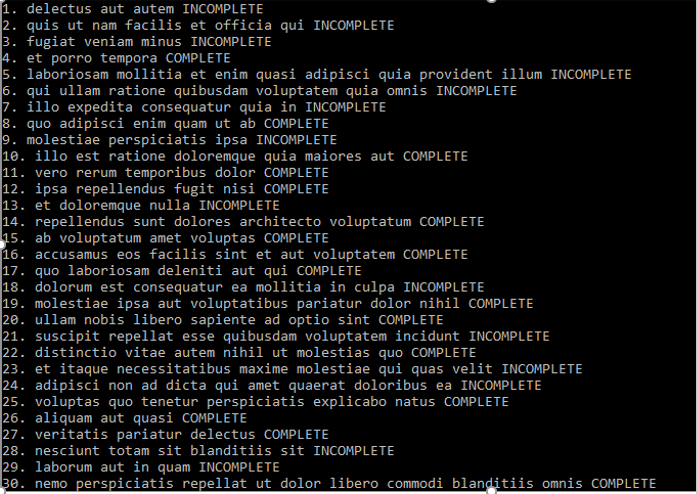
So far so good, our classes all work and the absence of loose coupling has yet to come back and bite us. But what if we need to use another service. There are several reasons why we would want to replace the ToDoService with something else:
• We might want to test our code with fake data provided by fake service
• We might want to support different sources of data like files, APIs or databases
• We might want to conditionally supply a service to the ToDos class according to some event
It’s hard to do so when the ToDos class heavily depends on a specific service implementation. As you might have guessed it’s time to get ourselves some loose coupling. Here’s what we need to do:
• Create a IToDoService interface that will be implemented by any supporting service
• Modify our ToDoService to implement the IToDoService interface
• Create a TestToDoService that also implements IToDoService
• Modify LooselyCoupledToDos to work with either service
The implementation of the IToDoService is pretty simple:
And in ToDoService:
Now let’s create another service that will return local data to the caller instead of calling an API or querying a database. This is a rather common practice during unit tests.
The TestToDoService implements the IToDoService differently. Instead of using an HttpClient to get JSON data from the web, this class creates a list and fills it up with some dummy data to be sent to the caller for testing
Now this is the most important step of them all! We need to go to our LooselyCoupledToDos class and make it support what its name says it supports. In order to do that, the class needs to hold a reference to an IToDoService object and not a ToDoService or TestToDoService object. It also needs to take that reference as a constructor argument rather than instantiating on its own. That way our LooselyCoupledToDo class knows nothing about the actual service and thus we will have achieved the precious separation of concerns we want.
Now that we’ve implemented our classes in a loosely coupled way let’s see how easy it is to switch services. Let’s introduce a static field in our Program class that will be true if the app is in test mode and therefore needs to use test data or false if the application is not in test mode and must fetch real data:
If _testMode is true the LooselyCoupledToDos is initialized with the test service, if it is not it gets initialized with the real service.
You can see the whole project in my GitHub repository dedicated to C# here
Now that you’ve learned what loose coupling is, it’s time to take it one step further and learn about Inversion Of Control and Dependency Injection. I will be writing on those soon. Until then, keep coding!!